One Platform. Infinite Vision Possibilities
just works.
Run detection, segmentation, pose estimation, and more — on images, video, or live streams. No GPU setup, no infrastructure. Just results.
Skip the complex setup.
No GPUs, no Docker, no env config. Just upload and run. Built for researchers who want results, not infrastructure.
Automate with your cameras.
Turn existing security cameras into smart analytics. No new hardware, no monthly contracts — just AI.
Medical Lab
AI-powered diagnostic imaging for researchers. MRI segmentation, 3D reconstruction, and volumetric analysis — all from your browser.
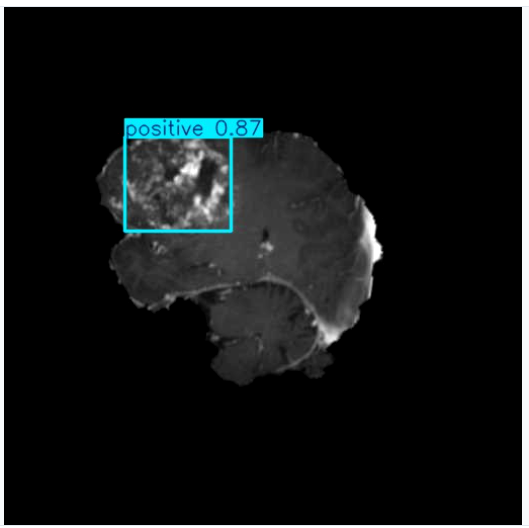
Brain Tumor & Neuro Diagnostics
Identify structural anomalies, track lesion progressions, and segment multi-class brain tissues in seconds.
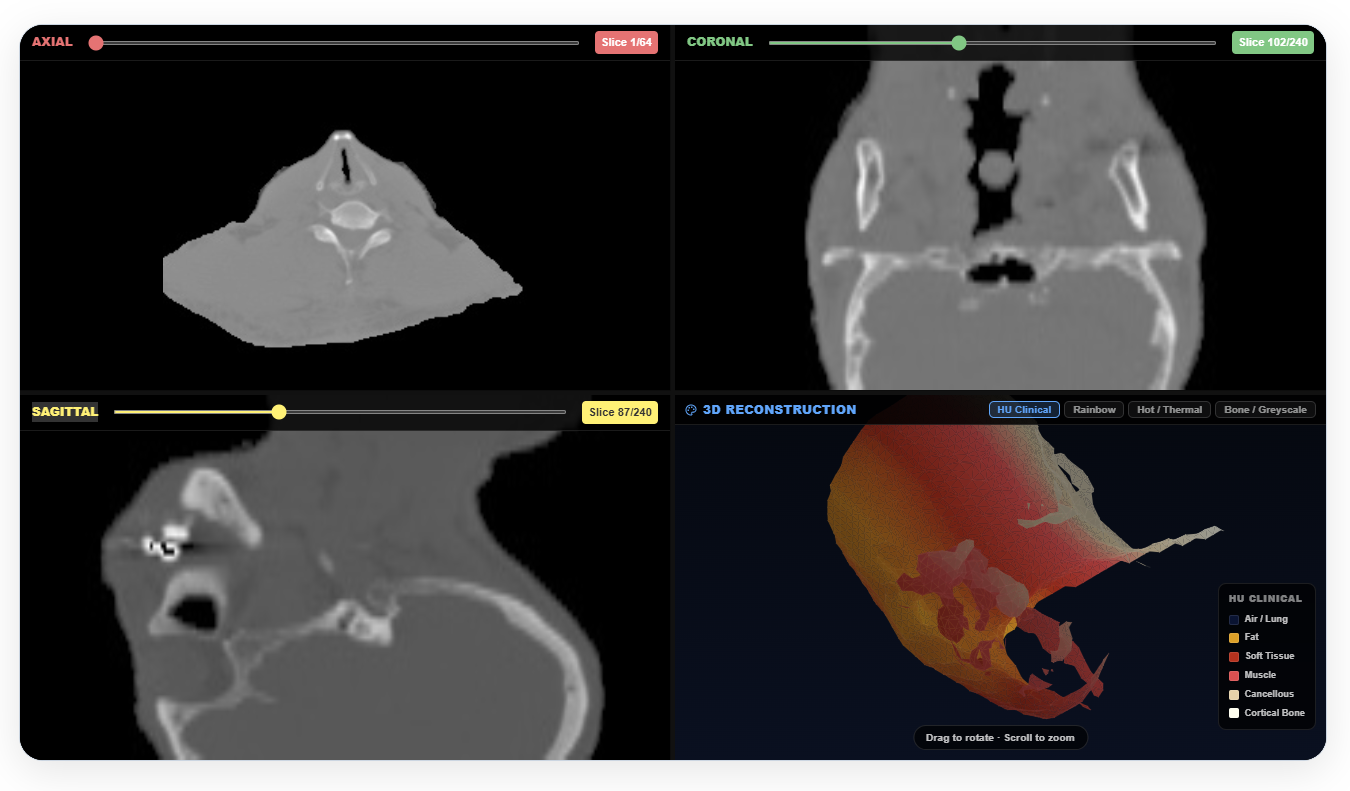
3D Reconstruction & Multi-Planar Slicing
Transform standard 2D DICOM slices into immersive 3D anatomical models with interactive tissue densities.
Specialized AI Labs
Purpose-built models for specific industry challenges — all from your browser.
Smart Parking Lab
Monitor lots, detect occupancy, automate vehicle counting.
Explore LabDrone & Aerial Lab
Analyze drone footage for asset inspection and monitoring.
Explore LabObject Tracking
Persistent tracking with ID stabilization and trajectory prediction.
Explore LabHeatmap Analytics
Identify high-traffic areas, optimize shop layout with AI.
Explore LabQueue Management
Optimize checkout and minimize wait times with AI monitoring.
Explore LabPrivacy & Blurring
Automated redaction for faces, plates, and sensitive data.
Explore LabEdge Detection Lab
Canny, Sobel, Laplacian operators for industrial inspection.
Explore LabImage Enhancement Lab
Contrast, detail, and color optimization with 10+ algorithms.
Explore LabTutorials & Notebooks
Ready-to-run Jupyter notebooks covering object detection, segmentation, tracking, OCR, and more. Open in Colab with one click.
Detection
YOLOv5 → YOLO26, DETR, RF-DETR, Grounding DINO, YOLO-World, and more.
Segmentation
SAM, SAM2, SAM3, FastSAM, PaliGemma, SegFormer, and custom pipelines.
Pose & Tracking
ByteTrack, SORT, OC-SORT, YOLO pose estimation, sports analytics.
Fine-Tuning
Custom dataset training for any model. LoRA, full fine-tune, and distillation guides.
Zero-Shot & VLMs
GPT-4o, Gemini, Florence-2, Qwen2.5-VL, CLIP, and open-vocabulary detection.
Classification & OCR
ViT, DINOv2, ResNet, PaddleOCR, GLM-OCR, LaTeX OCR, and scene text.
Computer Vision Research & News
Stay at the cutting edge. Curated papers, conferences, and model releases — updated for 2026.
VGGT: Visual Geometry Grounded Transformer
CVPR 2025 Best Paper winner. An end-to-end transformer model that solves camera estimation, depth, and correspondences in seconds without bundle adjustment.
Meta Releases Segment Anything 2.1 (SAM 2.1)
Major update to the Segment Anything foundation model, featuring enhanced video tracking stability, native code optimizations, and official PyTorch integration.
Ultralytics YOLO26 Flagship Release
The new flagship real-time detector. Features NMS-free (Non-Maximum Suppression) architecture, MuSGD optimizer, and removes DFL parameters for sub-5ms latency.
RT-DETRv4: VFM Distillation for Lightweight Detectors
A distillation framework that transfers semantic knowledge from large Vision Foundation Models to real-time DETRs, boosting AP by 4.5% without latency penalties.
Molmo & PixMo: Open Weights Vision-Language Models
A state-of-the-art suite of open-weights VLMs performing at par with proprietary systems in spatial reasoning, charting, and detailed document understanding.
CVPR 2026 Set to Open in Denver, Colorado
The premier annual computer vision event starts June 3-7, featuring extensive workshops, tutorials, and primary focus tracks on embodied AI and synthetic datasets.
Explore the global SOTA landscape
Complete proceedings, open-access libraries, and real-time model leaderboards.